小市值因子的有效性已经被无数人证明。在聚宽平台上只要是看上去年化收益还可以的有很多其实都用到了小市值因子。当然上面还有给小市值因子加上很多择时的(如RSRS择时等)。 我们来看看只用一个小市值因子能有怎么样的年化收益率。该策略的思路很简单:
- 全市场选股,过滤掉st,停牌,科创板,次新股,当天涨跌停的股票
- 按市值升序排列,选取市值最小的10只股票(我这里稍微做的一个改进是首先去除了市值最低的10%那部分股票,当然你也可以把这个限制条件去掉,我对比了一下收益变化不是很大)
我们先来看一下过去10年的一个回测结果
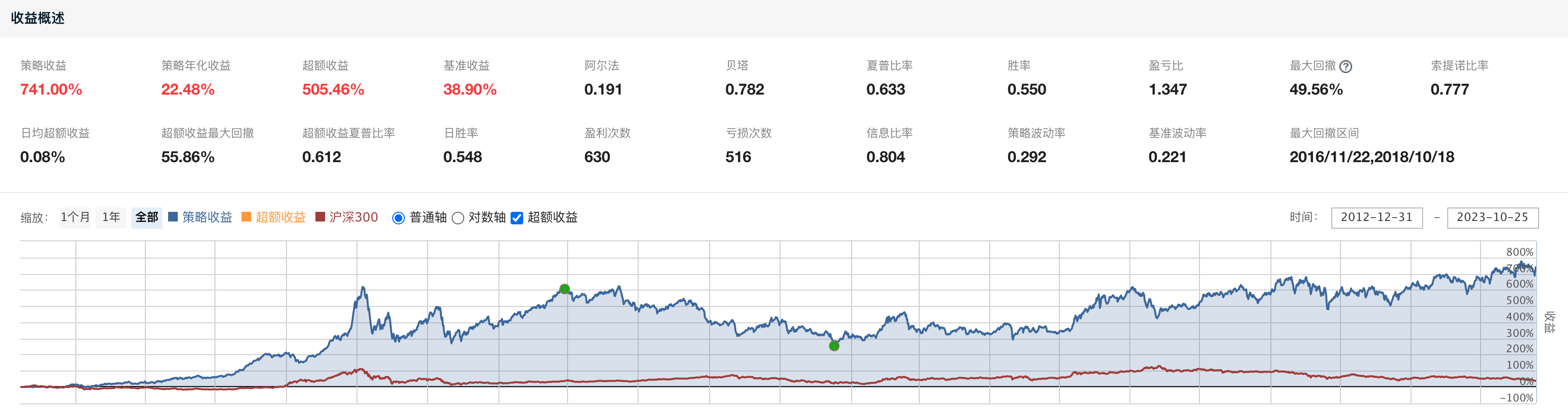
可以看到单单使用一个市值因子,就能在过去10年当中取得年化收益22.48%的成绩,不得不说确实很惊人。也有很多人说小市值因子在历史上很管用但是最近几年已经失效了,那么我们来看看今年小市值因子的表现。
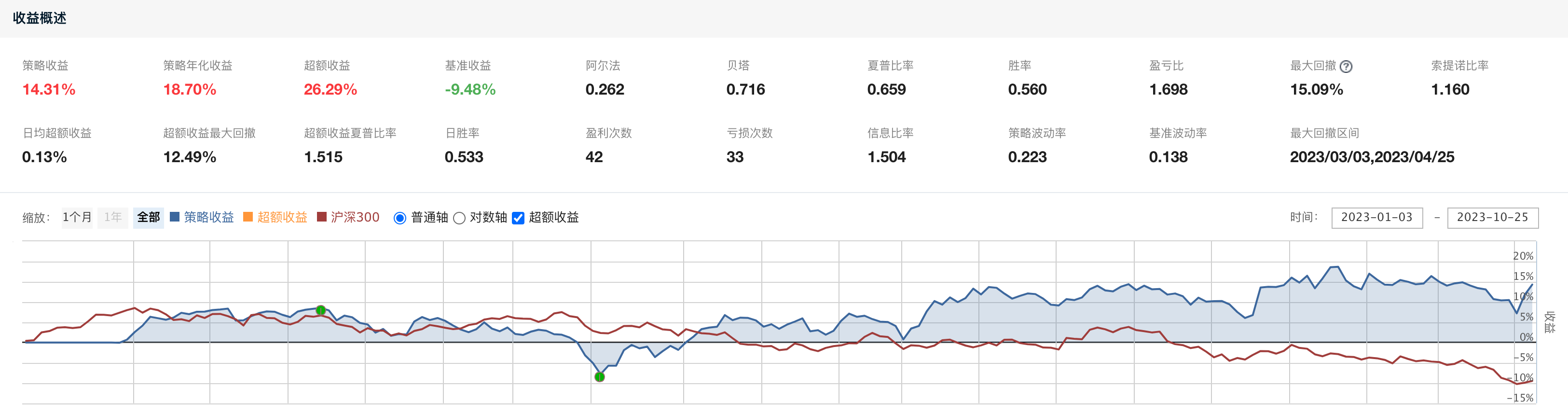
可以看到,就算是今年,在沪深300跌了快10%的情况下(截止2023年10月26号),我们的小市值因子也取得了年化18%的好收益。 很多做量化的有个误区,就是模型越复杂越好,最好是把深度神经网络,CNN,RNN一大堆东西都融进模型里面去。其实有时候赚钱的模型反而是很简单的模型。基金也好,投资机构也好,他们把自己的模型说的天花乱坠,各种AI,深度神经网络,其实是为了卖他们的产品。越复杂的模型,会让购买者越觉得这个钱花得值。但是,我们始终不能忘记投资的第一性原理:赚钱,我自己的实盘模型也用到了小市值因子。
特别需要注意的是,小市值因子也有个显著的问题可能在回测中是看不出来的。当你的资金量变大的时候,小市值因子就会慢慢失效,因为你的资金量开始对市场产生冲击。从A股的情况来看,很多公司的市值也就20亿左右,一天的成交量少的只有1000万。如果你一个人就买了100万的股票,就会自己把股价推高,从而提升你的成本,卖出去的时候同理。此外,可能还会存在流动性问题。所以小市值模型是容纳不了太多的资金的。
最后附上代码供参考:
# 导入函数库
import jqdata
from jqlib.technical_analysis import *
from jqdata import *
import warnings
from datetime import date
import numpy as np
# 初始化函数
def initialize(context):
# 滑点高(不设置滑点的话用默认的0.00246)
set_slippage(FixedSlippage(0.02))
# 沪深300
set_benchmark('000300.XSHG')
# 用真实价格交易
set_option('use_real_price', True)
set_option("avoid_future_data", True)
# 过滤order中低于error级别的日志
log.set_level('order', 'error')
warnings.filterwarnings("ignore")
# 选股参数
g.stock_num = 10 # 持仓数
g.position = 1 # 仓位
# 手续费
set_order_cost(OrderCost(close_tax=0.001, open_commission=0.0005, close_commission=0.0005, min_commission=5), type='stock')
# 设置交易时间
run_monthly(my_trade, monthday=-4, time='14:30', reference_security='000300.XSHG')
# 开盘时运行函数
def my_trade(context):
yesterday = context.previous_date
check_out_list = get_stock_list(context)
log.info('今日自选股:%s' % check_out_list)
adjust_position(context, check_out_list)
# 2-2 选股模块
def get_stock_list(context):
yesterday = context.previous_date
# 过滤次新股
by_date = yesterday - datetime.timedelta(days=250) #
initial_list = get_all_securities(date=by_date).index.tolist()
# 过滤当日涨跌停,st,科创板,停牌
stock_list = filter_limit_stock(context, initial_list)
stock_list = filter_st_stock(stock_list)
stock_list = filter_kcb_stock(stock_list)
stock_list = filter_paused_stock(stock_list)
# 1. 选出小市值前20%股票
q = query(
valuation.code
).filter(
valuation.code.in_(stock_list)
).order_by(
valuation.market_cap.asc()
)
df = get_fundamentals(q).dropna()
low_cap_list = list(df.code)[int(0.1*len(list(df.code))):int(0.2*len(list(df.code)))]
return low_cap_list[:g.stock_num]
# 过滤涨跌停股票
def filter_limit_stock(context, stock_list):
current_data = get_current_data()
holdings = list(context.portfolio.positions)
return [stock for stock in stock_list if (stock in holdings) or
(current_data[stock].low_limit < current_data[stock].last_price and
current_data[stock].last_price < current_data[stock].high_limit)]
# 过滤停牌股票
def filter_paused_stock(stock_list):
current_data = get_current_data()
return [stock for stock in stock_list if not current_data[stock].paused]
# 过滤ST及其他具有退市标签的股票
def filter_st_stock(stock_list):
current_data = get_current_data()
return [stock for stock in stock_list if not (
current_data[stock].is_st or
'ST' in current_data[stock].name or
'*' in current_data[stock].name or
'退' in current_data[stock].name)]
# 过滤科创板
def filter_kcb_stock(stock_list):
return [stock for stock in stock_list if not stock.startswith('688')]
#过滤模块-创业板
def filter_cyb_stock(stock_list):
return [stock for stock in stock_list if stock[0:3] != '300']
def adjust_position(context, buy_stocks):
for stock in context.portfolio.positions:
if stock not in buy_stocks:
order_target(stock, 0)
position_count = len(context.portfolio.positions)
if g.stock_num > position_count:
value = context.portfolio.cash * g.position / (g.stock_num - position_count)
for stock in buy_stocks:
if stock not in context.portfolio.positions:
order_target_value(stock, value)
if len(context.portfolio.positions) == g.stock_num:
break